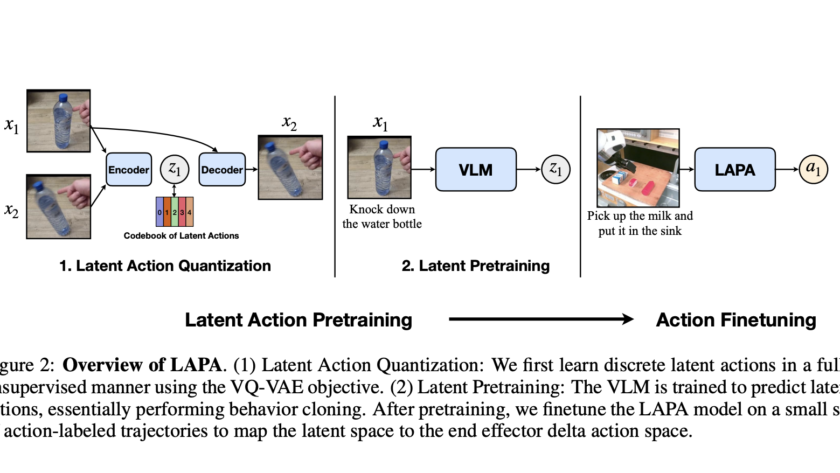
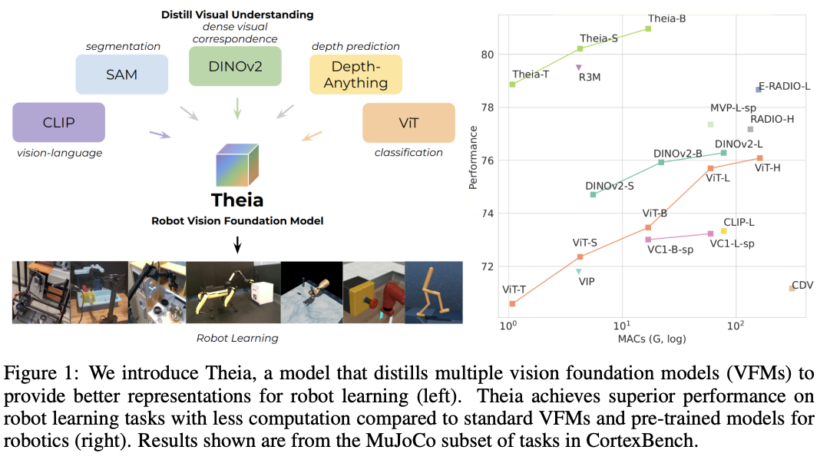
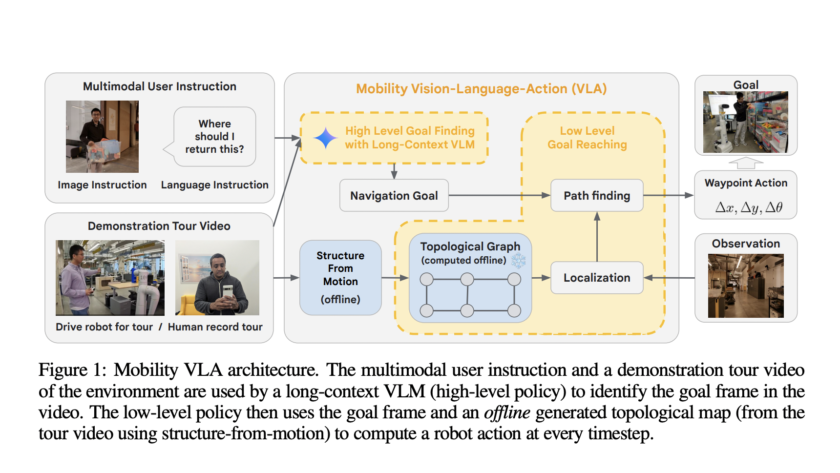
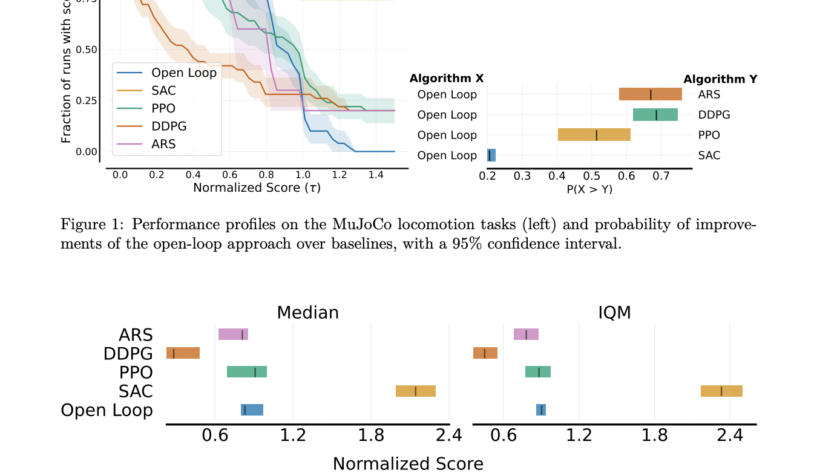
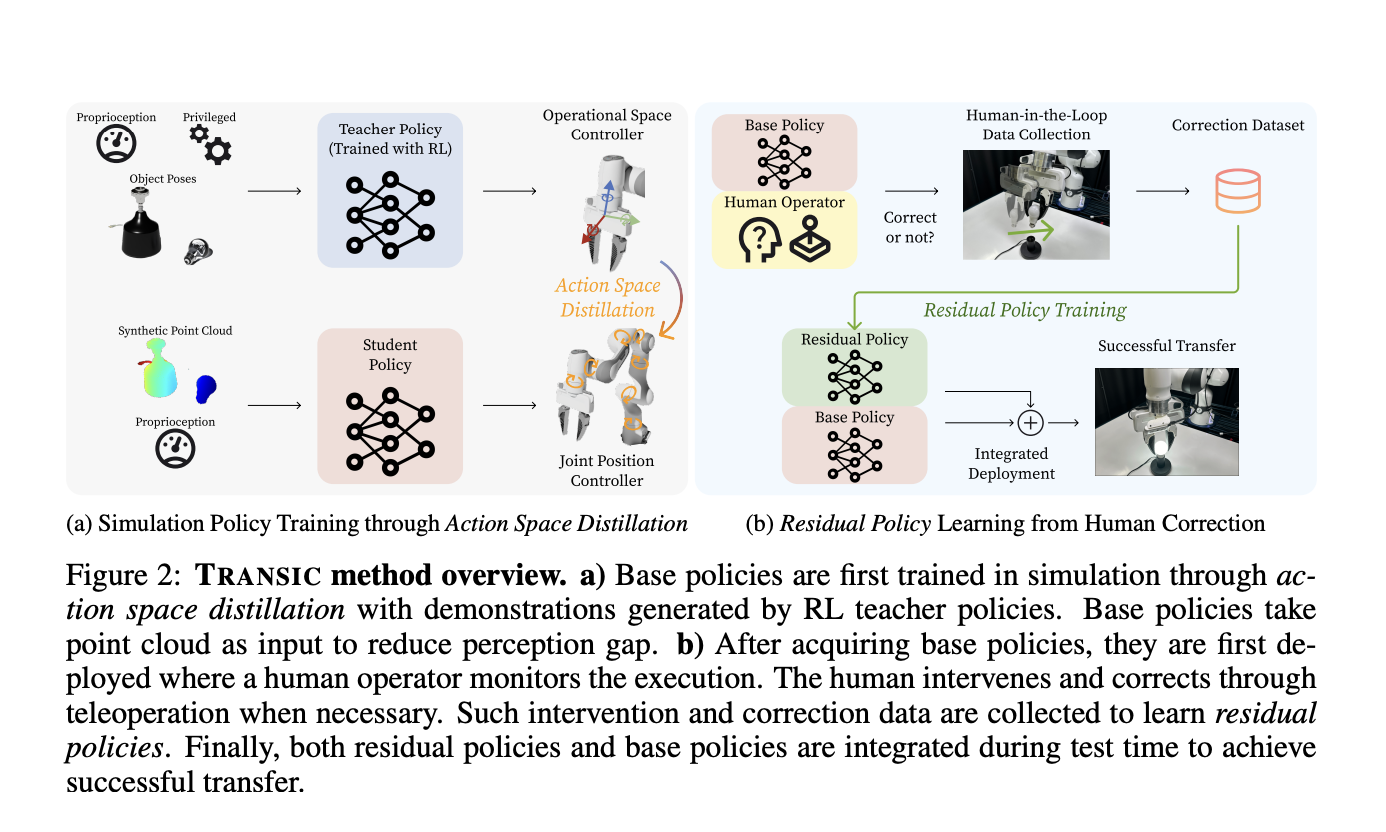
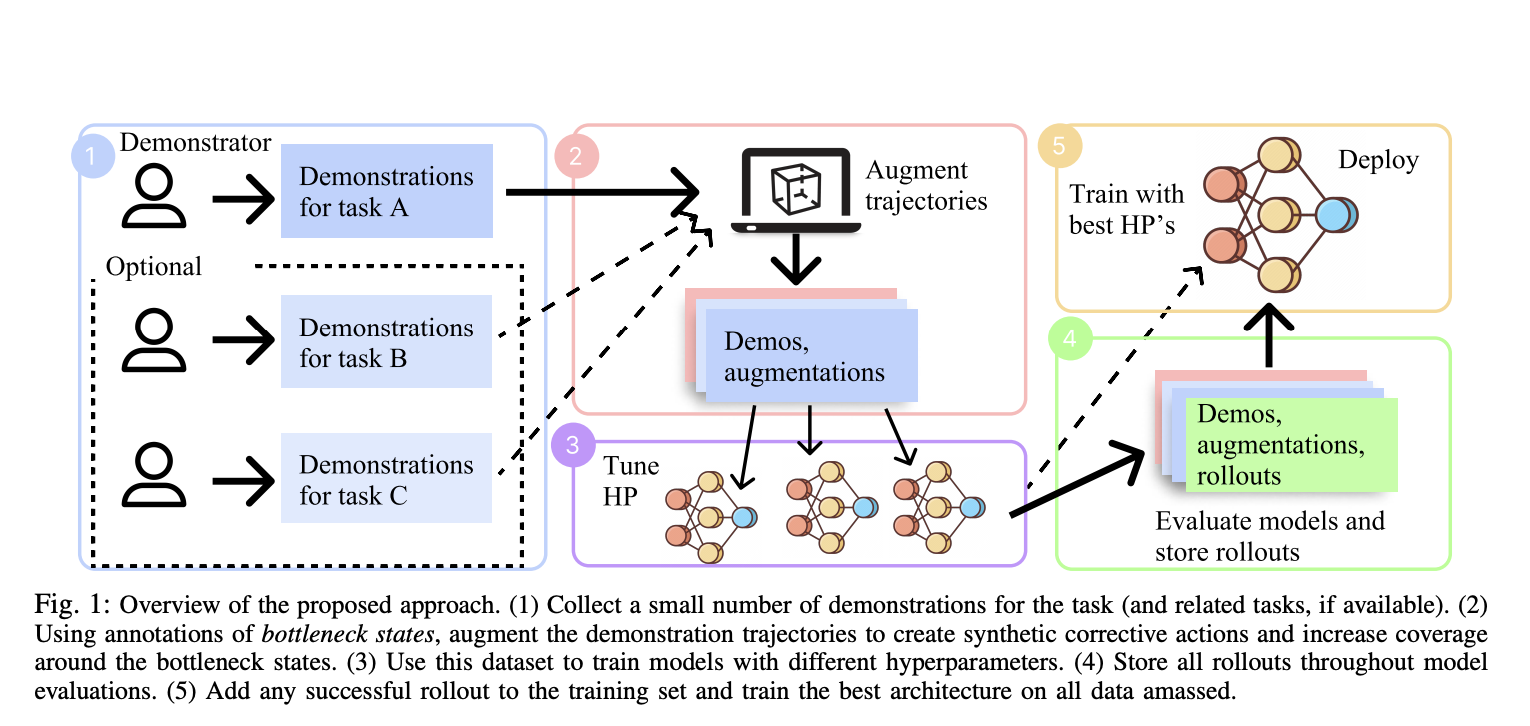
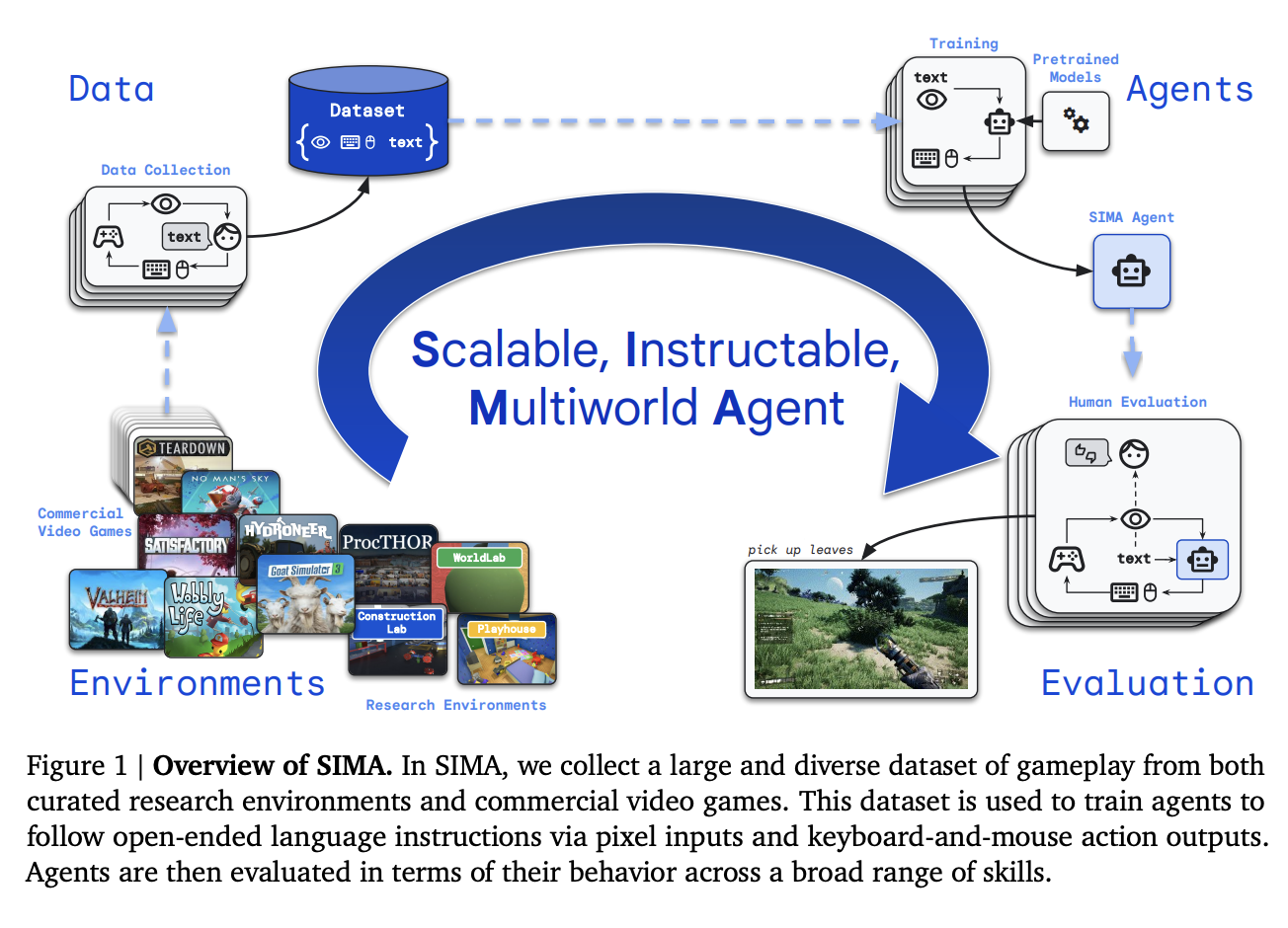
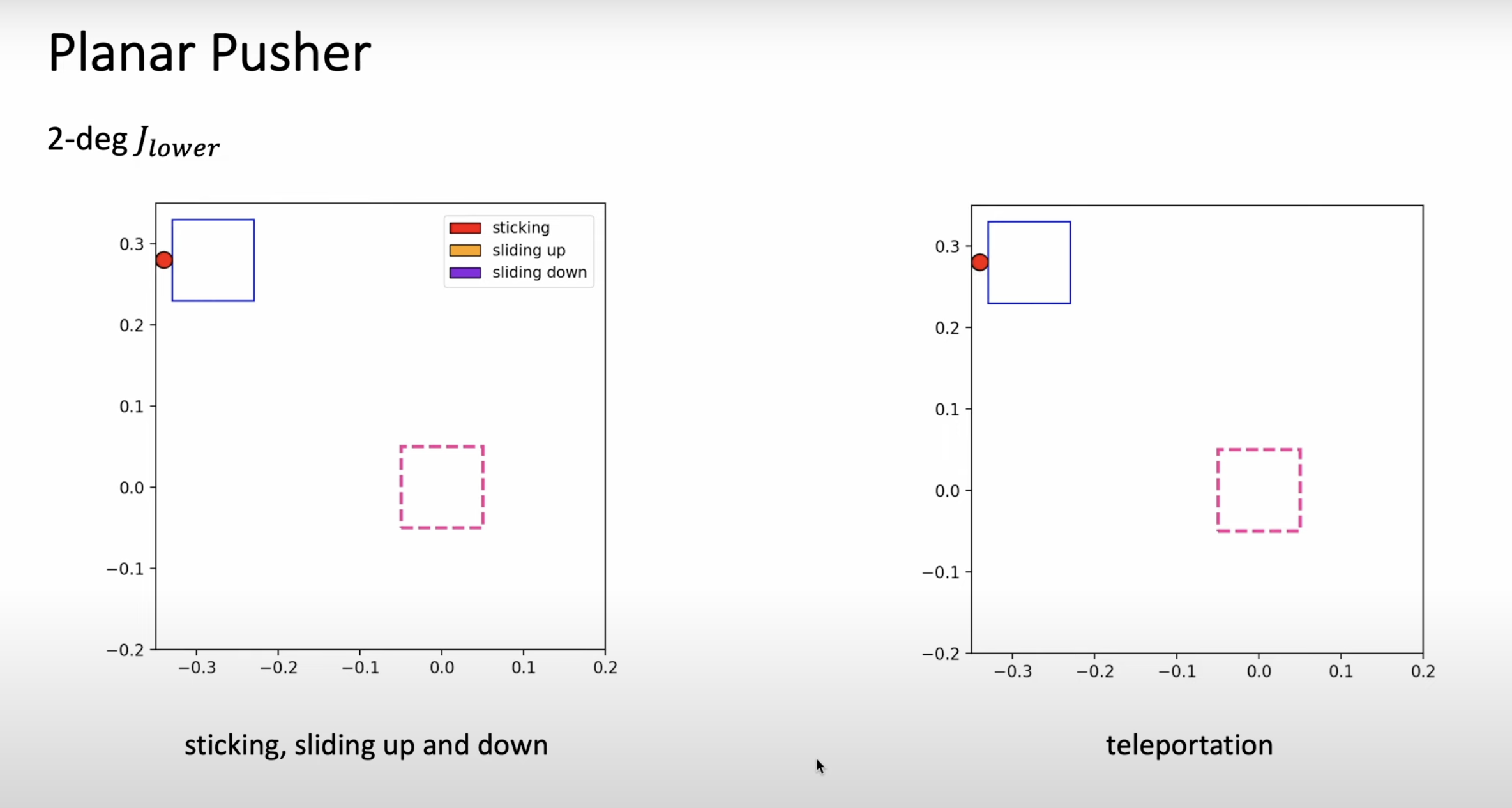
Vision-Language-Action Models (VLA) for robotics are trained by combining large language models with vision encoders and then fine-tuning them on various robot datasets; this allows generalization to new instructions, unseen objects, and distribution shifts. However, various real-world robot datasets mostly require human control, which makes scaling difficult. On the other hand, Internet video data offers…