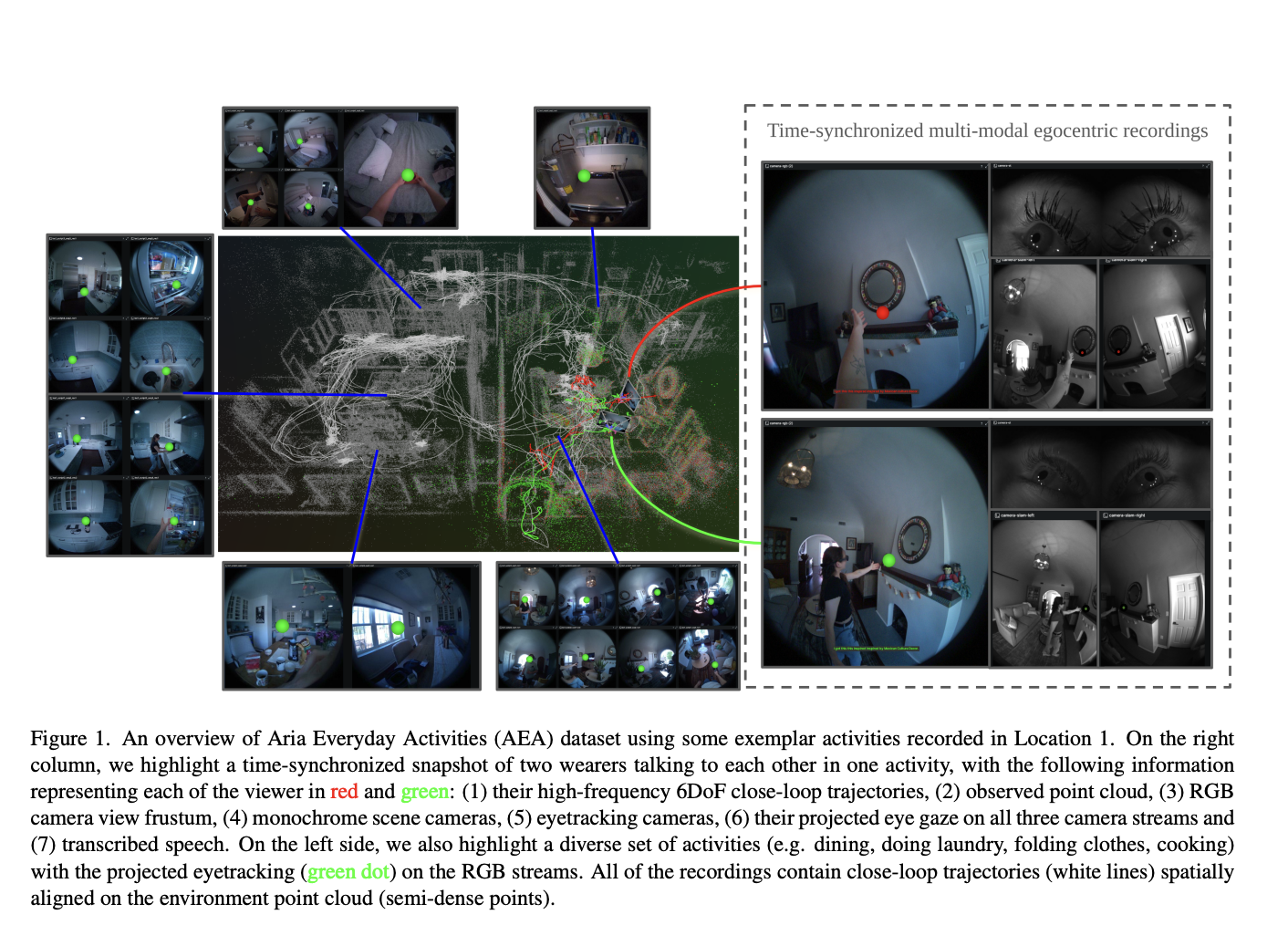
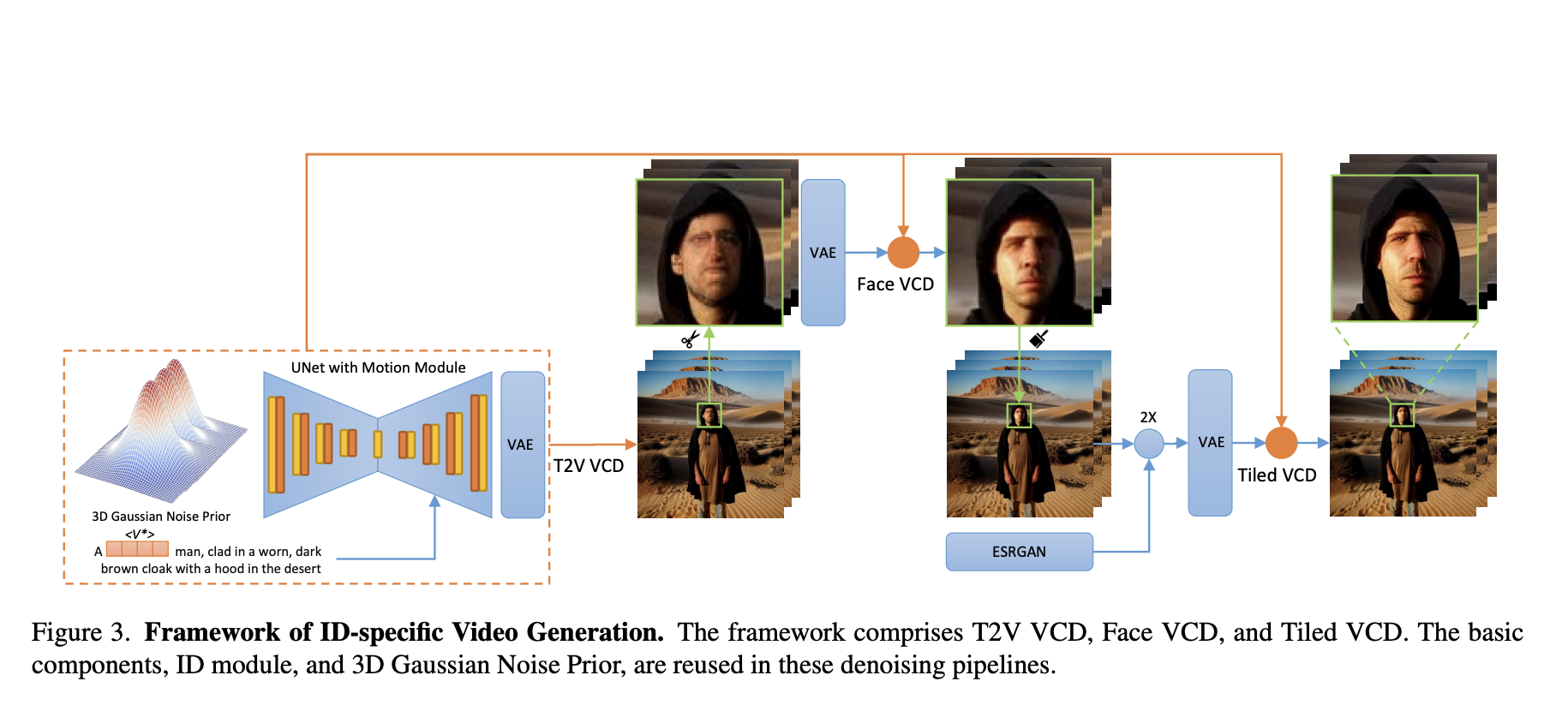
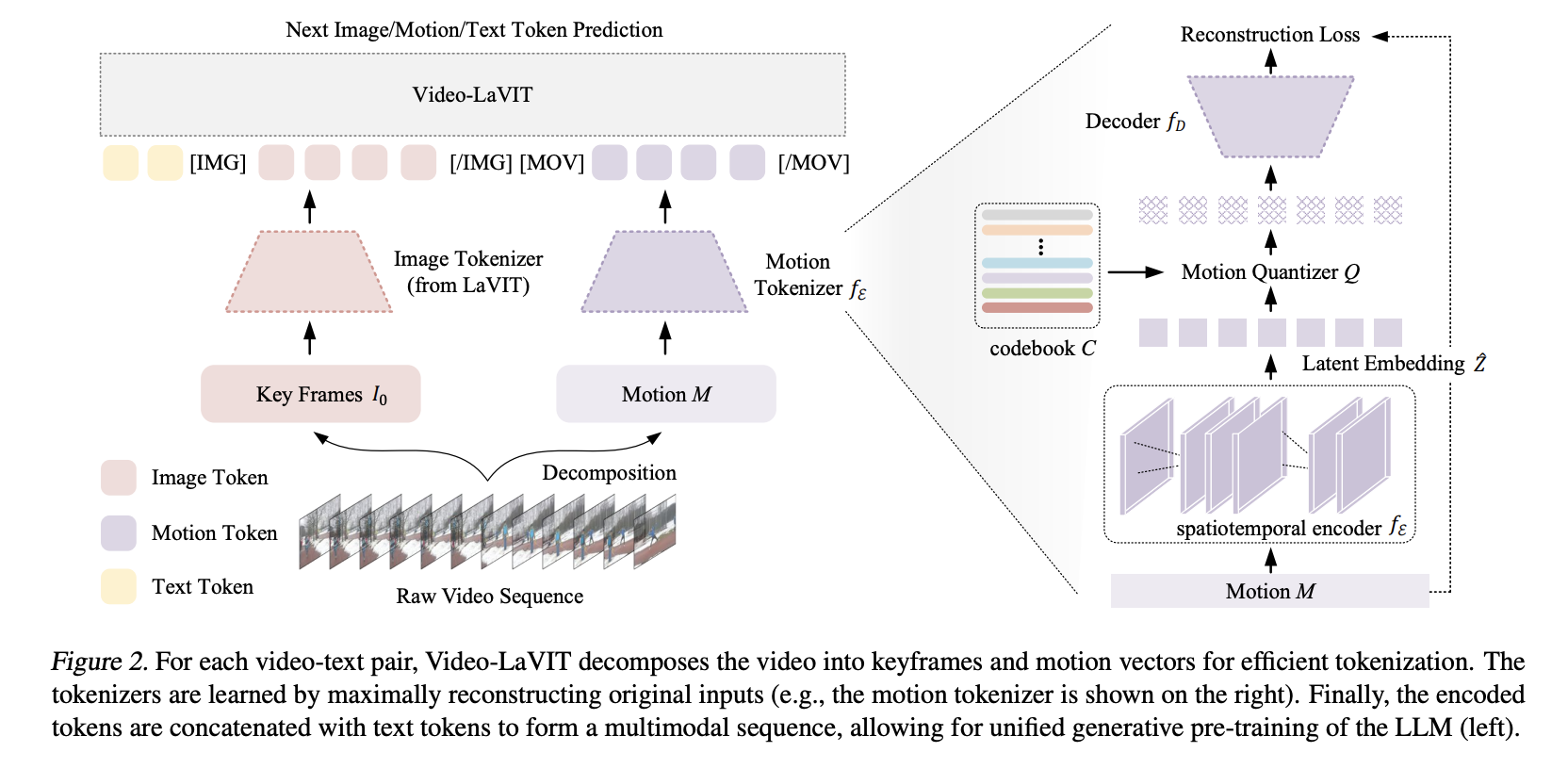
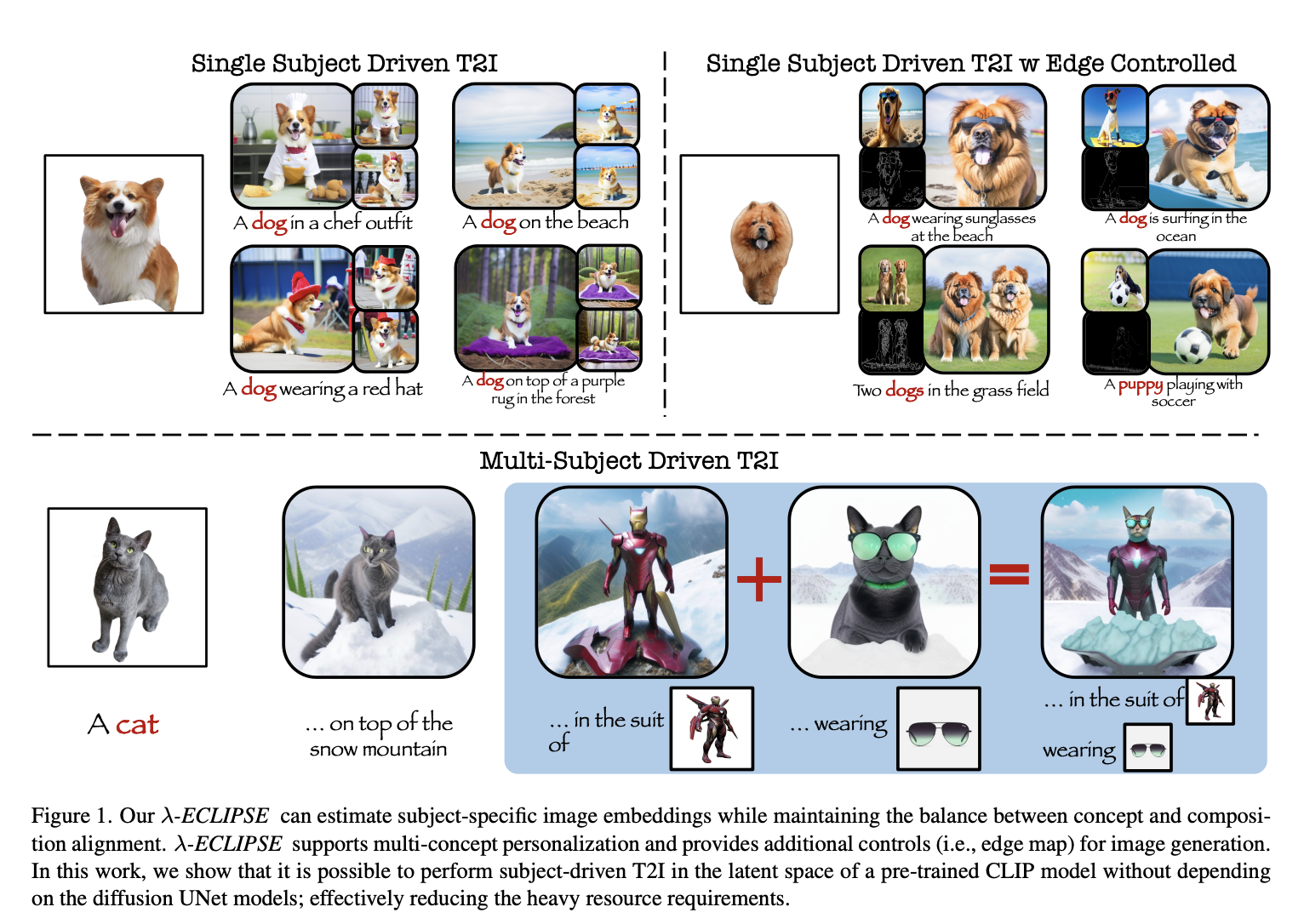
Google researchers address the challenges of achieving a comprehensive understanding of diverse video content by introducing a novel encoder model, VideoPrism. Existing models in video understanding have struggled with various tasks with complex systems and motion-centric reasoning and demonstrated poor performance across different benchmarks. The researchers aimed to develop a general-purpose video encoder that can…