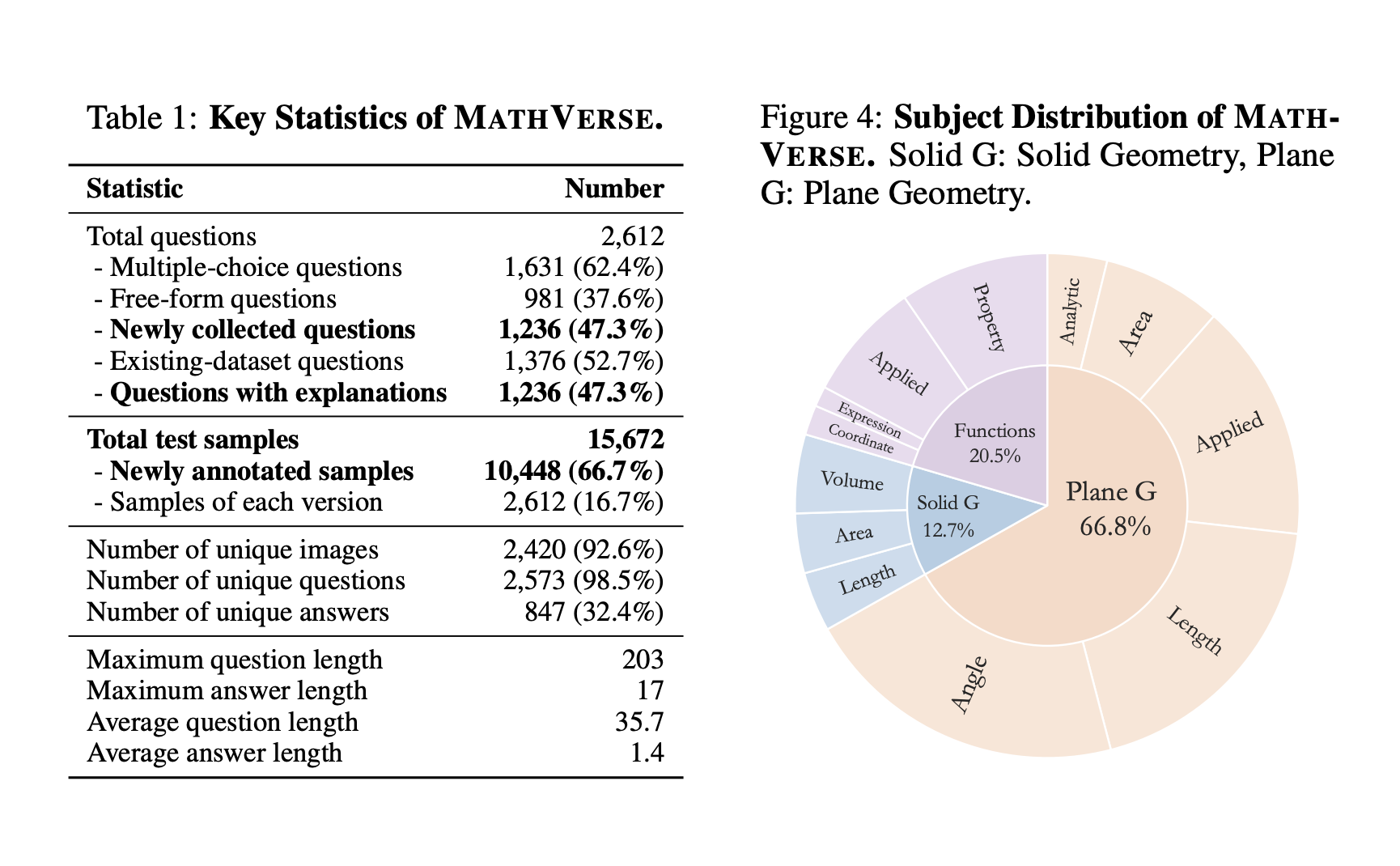
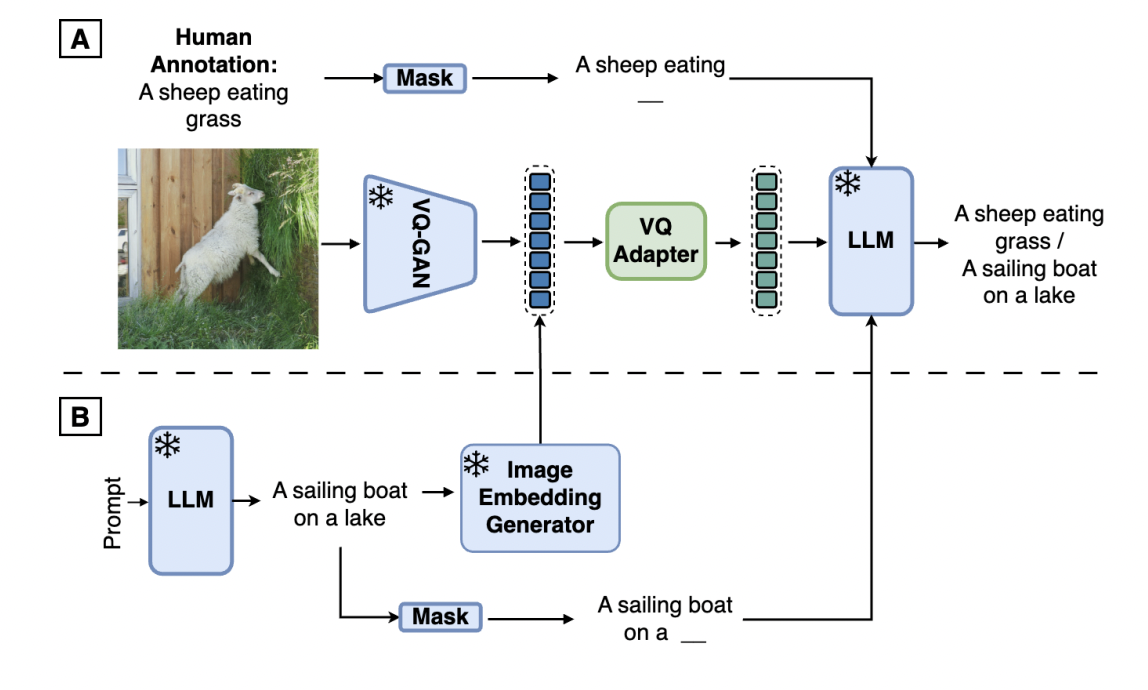
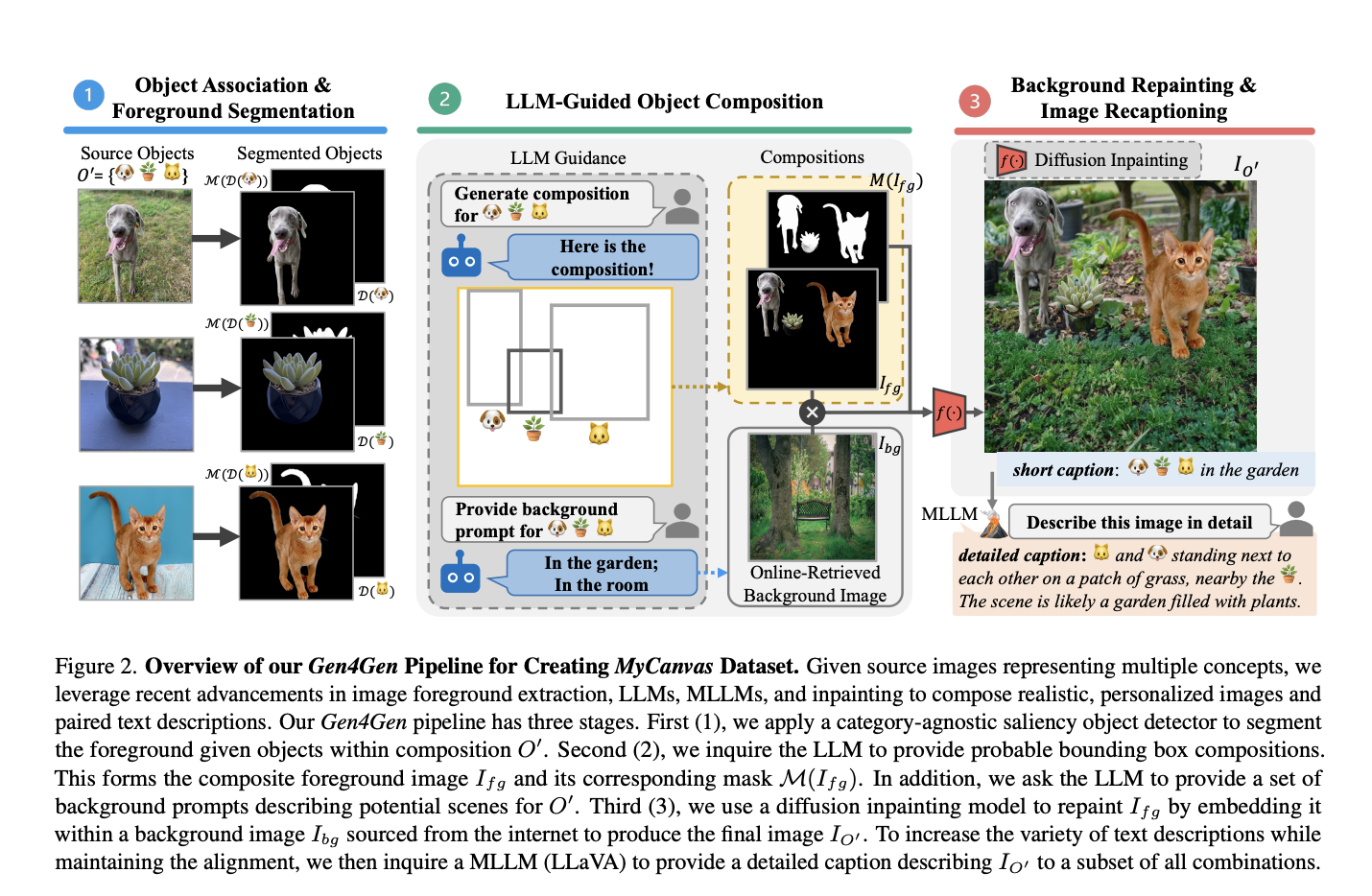
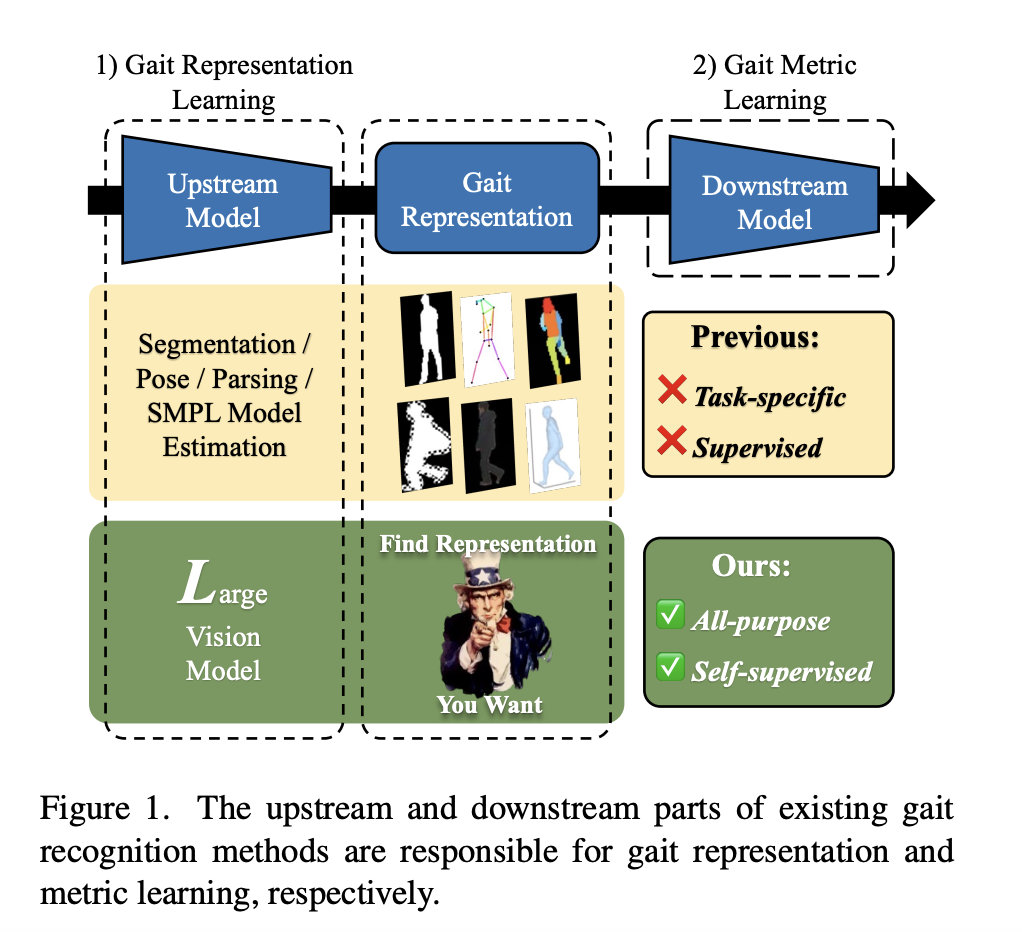
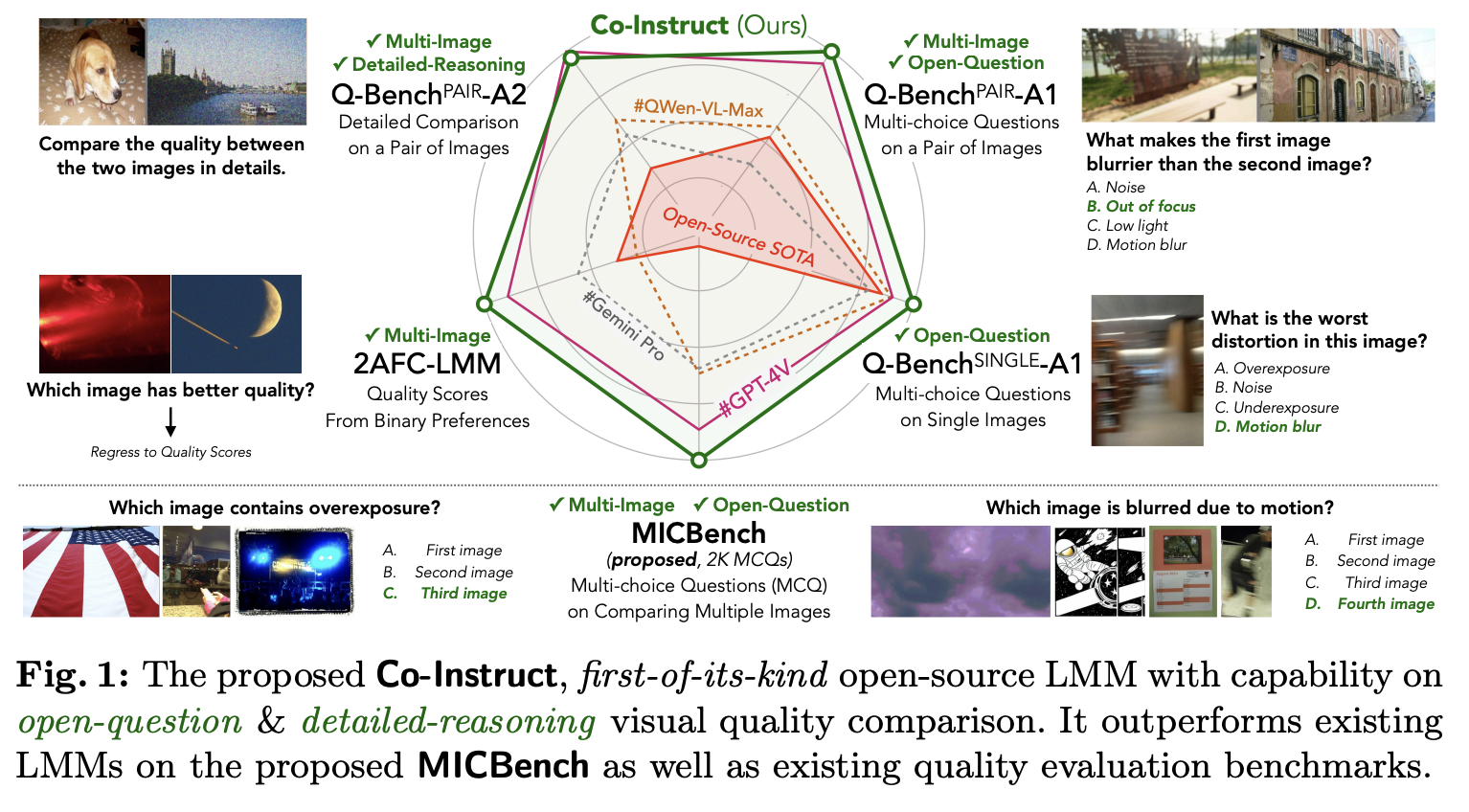
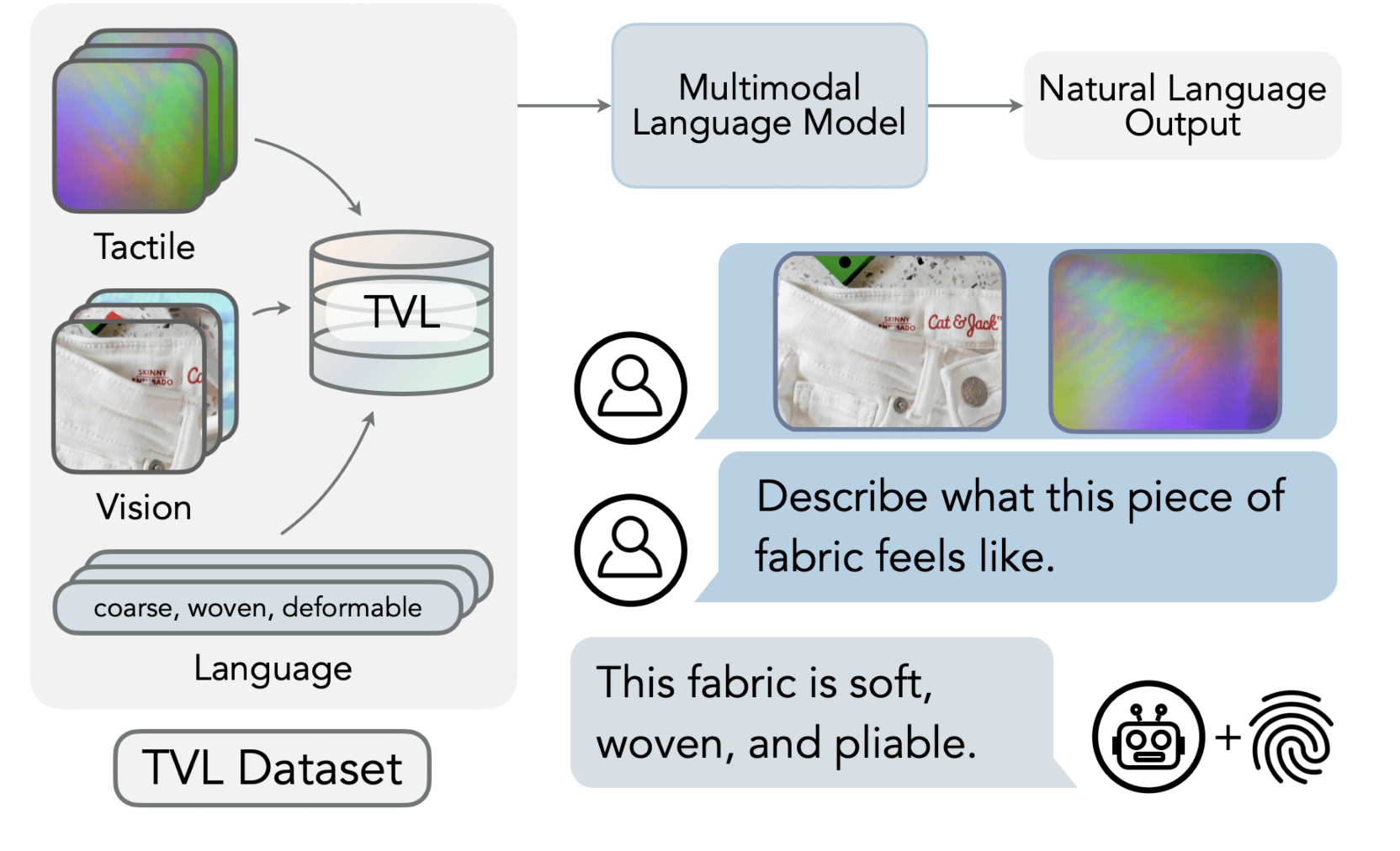
Large Language Models (LLMs) have proven their impressive instruction-following capabilities, and they can be a universal interface for various tasks such as text generation, language translation, etc. These models can be extended to multimodal LLMs to process language and other modalities, such as Image, video, and audio. Several recent works introduce models that specialize in…