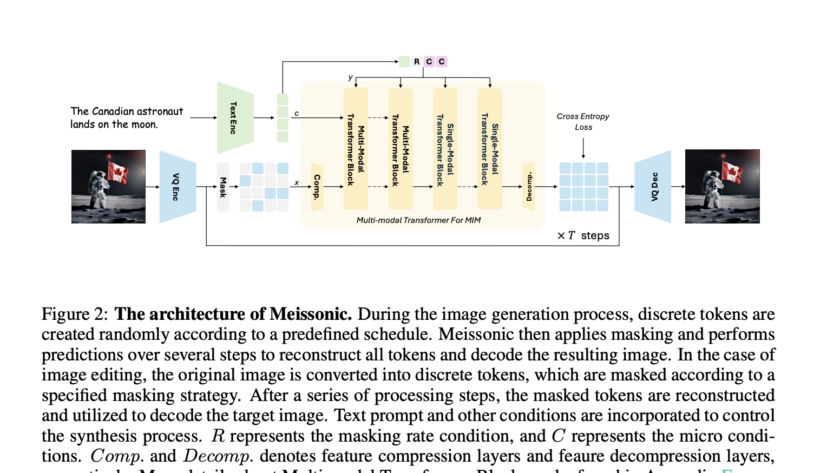
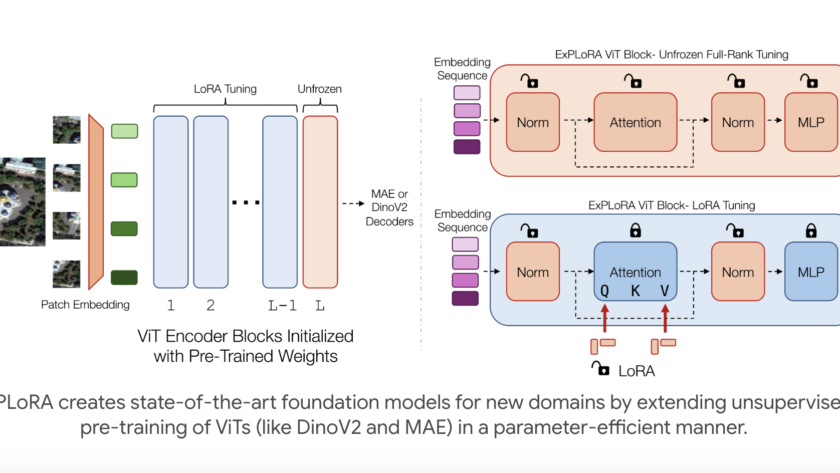
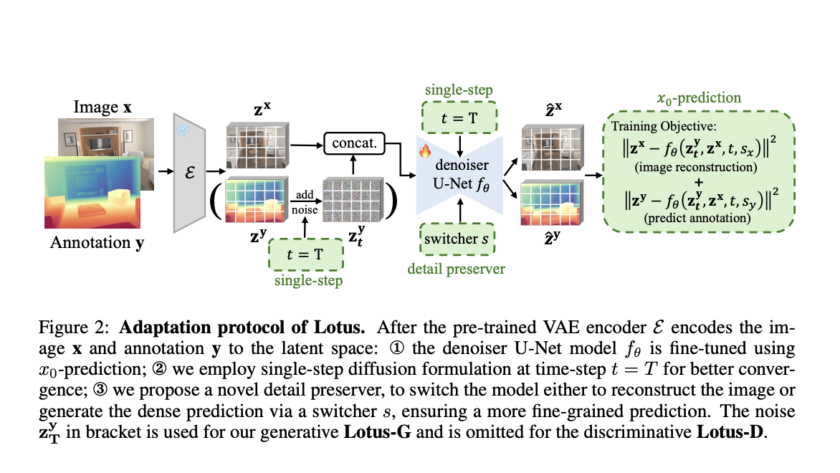
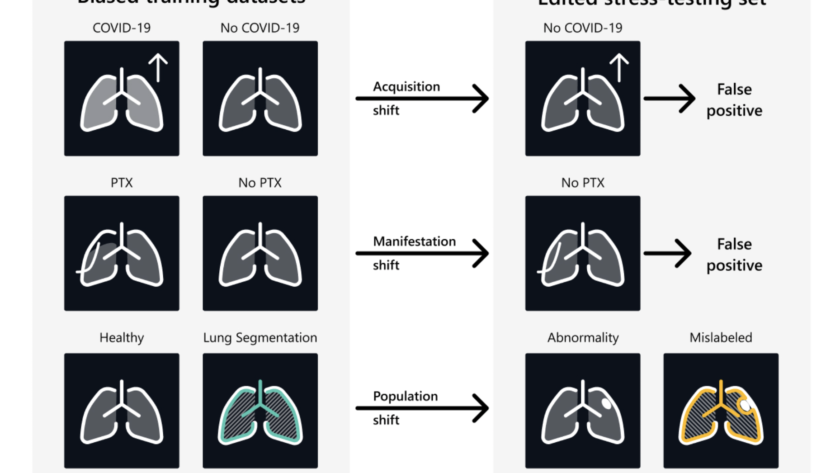
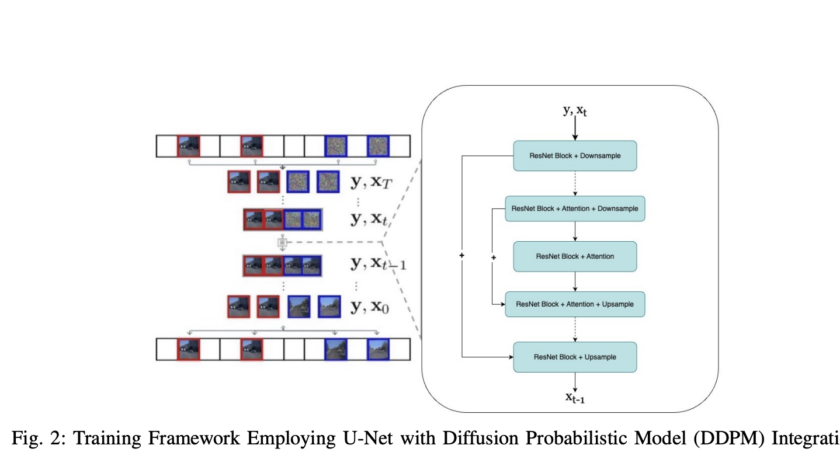
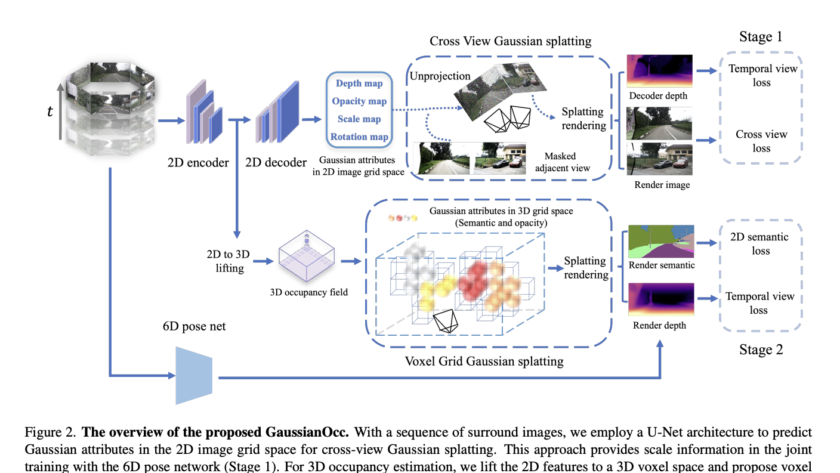
Large Language Models (LLMs) have demonstrated remarkable progress in natural language processing tasks, inspiring researchers to explore similar approaches for text-to-image synthesis. At the same time, diffusion models have become the dominant approach in visual generation. However, the operational differences between the two approaches present a significant challenge in developing a unified methodology for language…